背景介绍
请先阅读上文了解基本概念:AI浅谈及如何手动搭建本地大模型。
通常需要在服务器搭建对外提供API等能力的服务,而且并不像启动时再去下载大模型文件,而是使用本地已经下载好或者微调过的大模型。
xinference简介
Xinference(Xorbits Inference)是一个开源平台,可以更简单方便的运行继承各种AI模型,并且可以对外提供API。其支持各种大模型,包括聊天&生成、工具、视觉、嵌入、重排序、图像、音视频(试验阶段)等。
前提条件
硬件环境
硬件:要求(本人硬件)
CPU:无具体要求,(R7 5800x)
内存:16G以上,推荐32G以上,(48G)
GPU:最好16G显存以上NVIDIA显卡(目前大模型基本都基于N卡CUDA),(RTX 4060Ti 16G)
硬盘:100G以上,最好1T以上,(2T SSD)
软件环境
环境(本人):
系统:Linux,(Archlinux,包管理器pacman)
软件:NVIDIA驱动程序,CUDA
python3.11(推荐可选:Anaconda/Miniconda管理环境)
网络:科学上网(下载大模型必要条件)
提前下载大模型
对话模型以gemma-2b-it为例,本人下载至本地路径:/datad/llm/models/google/gemma-2b-it
嵌入模型以bge-m3为例,本人下载至本地路径:/datad/llm/models/BAAI/bge-m3
xinference搭建
- 安装依赖
1
2
3
4(optional) conda create -n xinference_env python=3.11 # 可选:新建conda环境
(optional) conda activate xinference_env # 可选:激活conda环境
pip config set global.extra-index-url "https://mirror.sjtu.edu.cn/pypi/web/simple" # 配置pip仓库镜像
pip install "xinference[transformers]" # 安装必要的包 - 启动项目并在web中查看web地址:http://localhost:9997/ui/
1
xinference-local # 在本地启动xinference
API文档地址(不准确,请至官方文档中查看):http://localhost:9997/docs - 启动本地对话模型
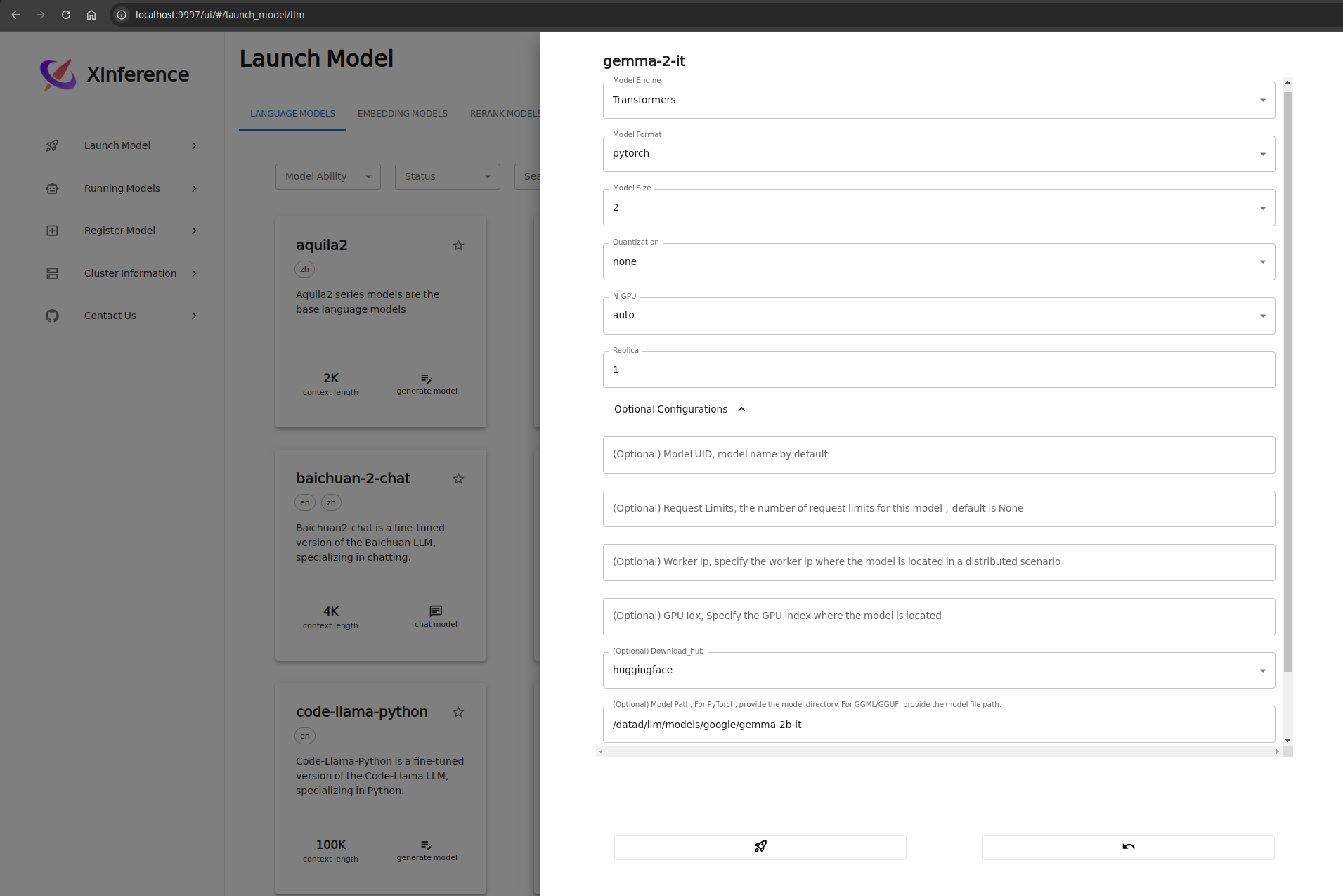
以启动gemma-2-it对话模型为例,配置如上图,可以配置本地模型路径,如果本地无模型,则会至对应的hub中下载模型;配置完成后点击火箭图标则可启动该模型。
通过docs界面可以发送API查看或者使用已启动的模型功能,具体使用方法参考Xinference官方文档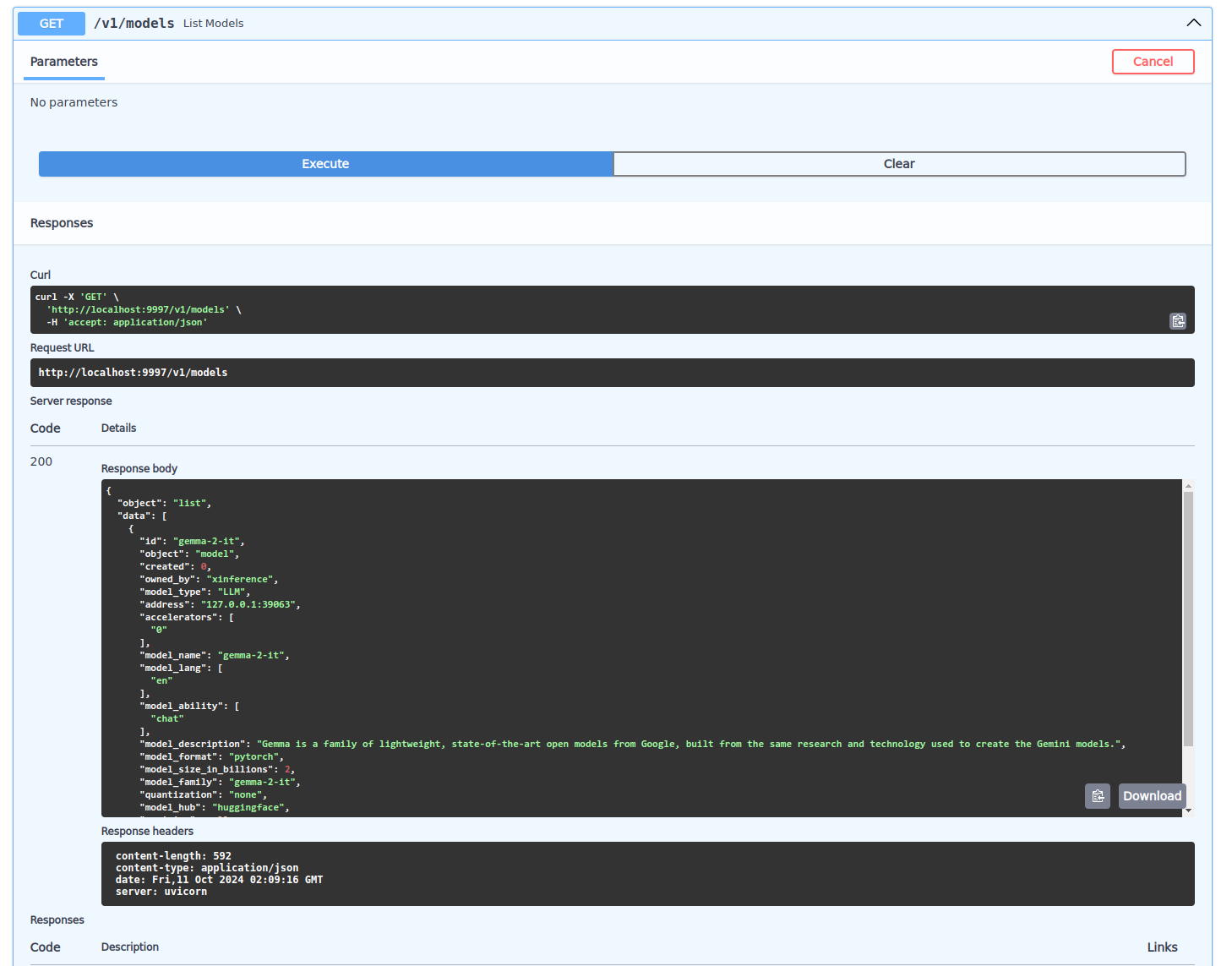
- 启动embeddings嵌入模型
配置与上一步骤中对话模型基本相同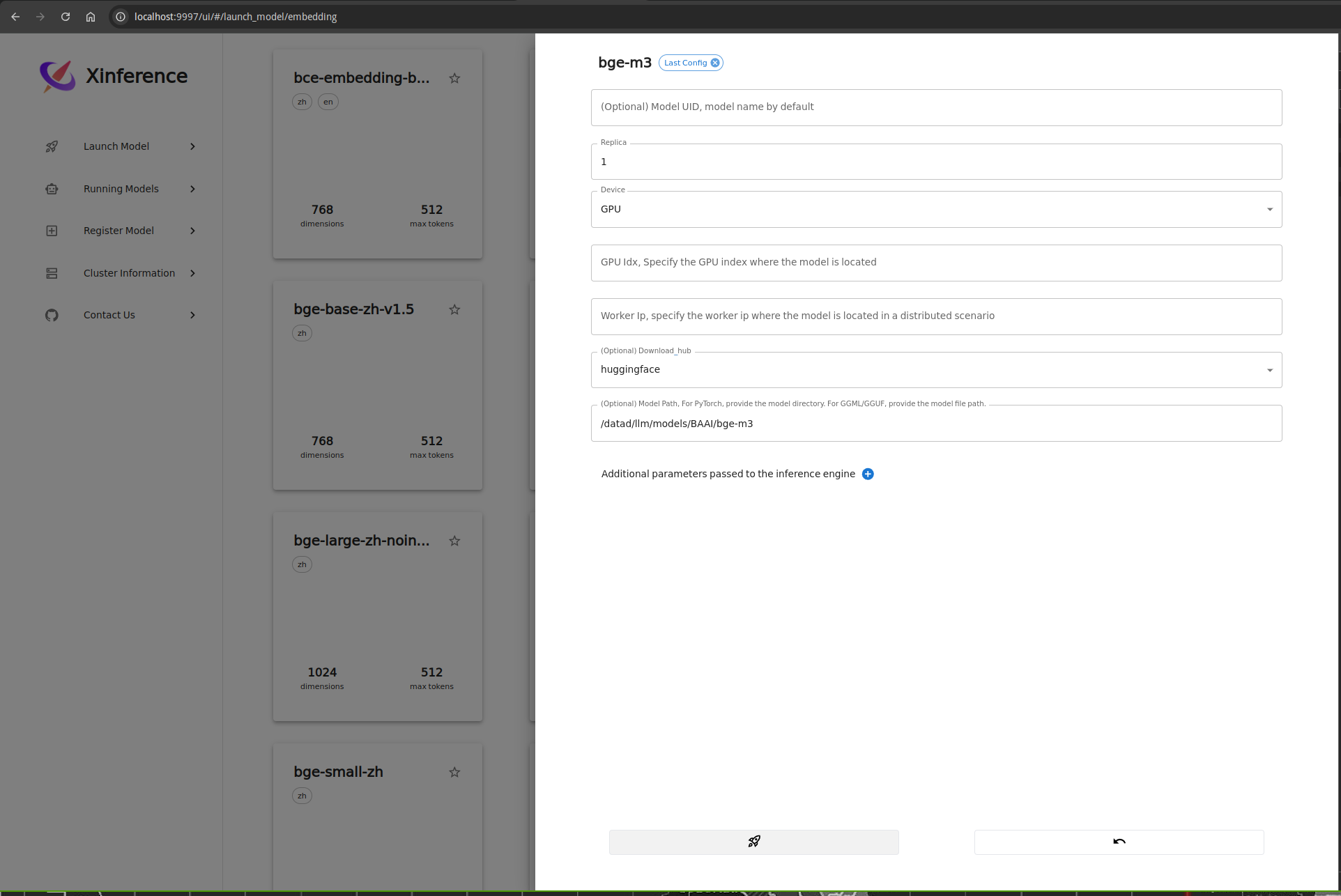
点击小火箭🚀图标启动,然后可以通过API接口调用对话模型的能力:1
2
3
4
5
6
7curl -X 'POST' 'http://localhost:9997/v1/embeddings' \
-H 'accept: application/json' \
-H 'Content-Type: application/json' \
-d '{
"model": "bge-m3",
"input": "What is the capital of China?"
}'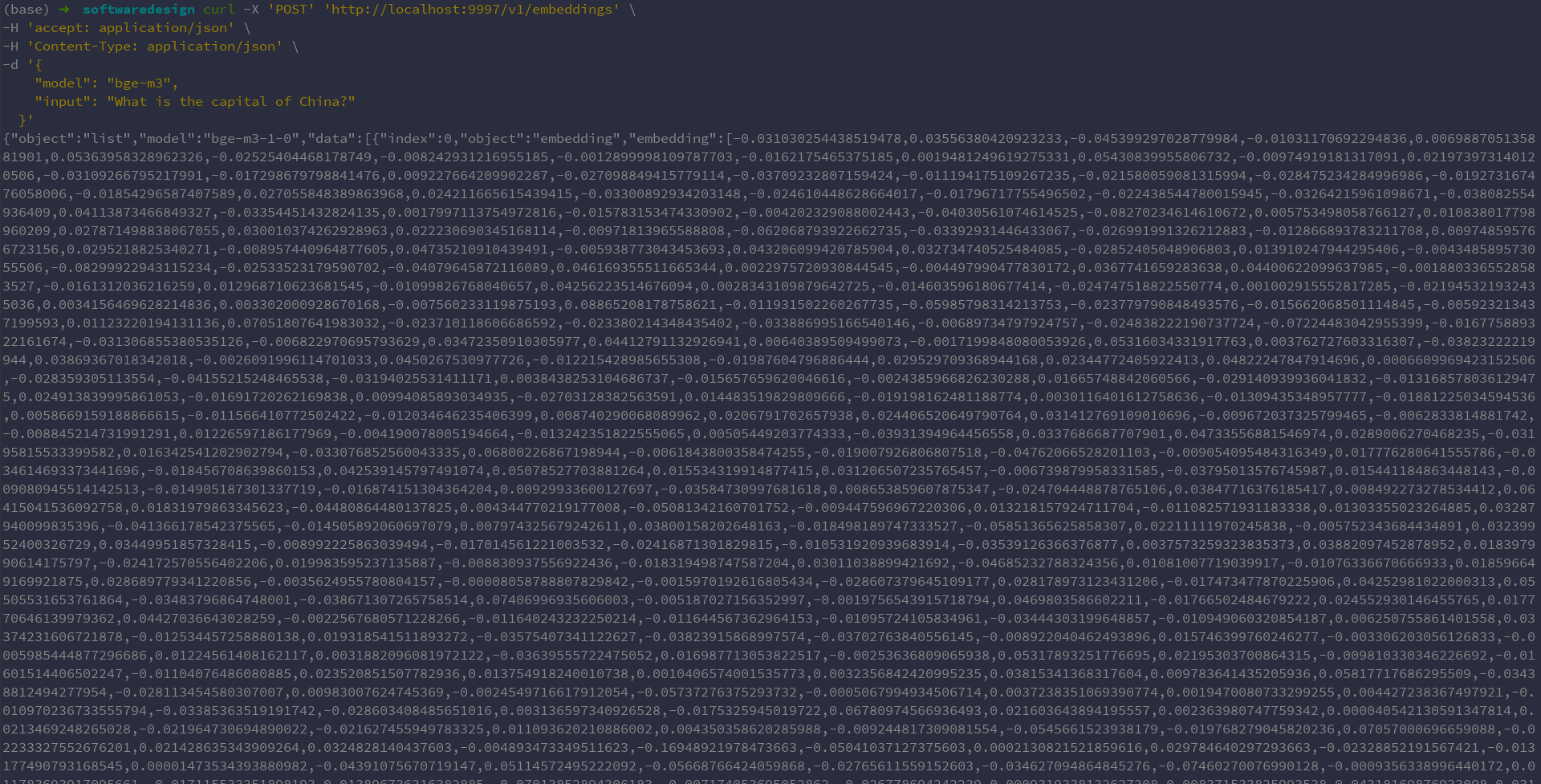
输出为输入文本的向量化表示。